
If you’ve been keeping tabs on the AI infrastructure space lately, you’ve probably noticed that the cost of running AI models — especially large language models — is one of the biggest headaches for developers and startups alike. Enter the Chutes API: a serverless, decentralized compute platform that’s quietly becoming one of the most talked-about tools in the open-source AI ecosystem. But what exactly is it, why does it matter, and how can you start using it today? Let’s dig in.
What Is the Chutes API?
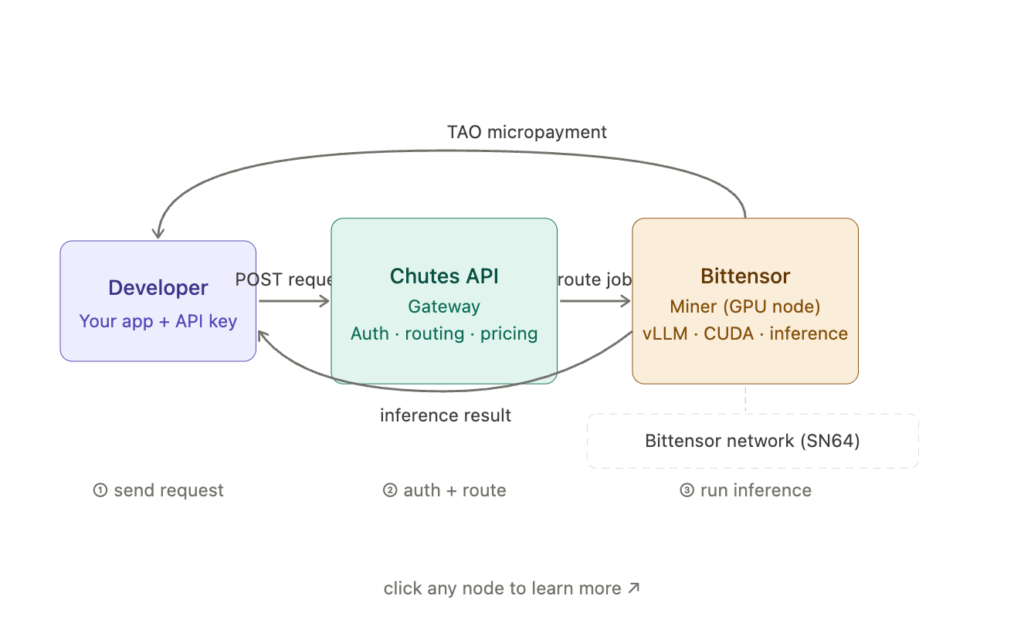
At its core, Chutes is a serverless AI compute platform built on top of the Bittensor decentralized network. It lets developers deploy, scale, and run open-source AI models — LLMs, image generators, speech models, video models — without ever having to manage GPU infrastructure themselves.
Think of it like this: instead of renting a server from AWS or Google Cloud, spinning up a Kubernetes cluster, and wrestling with CUDA drivers at 2am, you just bring your Python code. Chutes handles the rest.
The platform operates as Subnet 64 on Bittensor, and it’s currently the #1 most active subnet on the entire Bittensor network by usage. That’s not a small distinction. As of late May 2025, Chutes was processing over 100 billion tokens per day — roughly a third of what Google’s AI services were handling a year prior.
Why the Chutes API Is Getting So Much Attention
The Cost Problem Is Real
Anyone who’s tried to build a production AI application on traditional cloud infrastructure knows the sticker shock. GPU time isn’t cheap. AWS, Azure and Google Cloud charge premium rates for the kind of GPU access serious AI workloads need. Chutes takes a radically different approach.
Because it taps a decentralized network of GPU providers with a crypto micropayment model, Chutes can deliver AI compute far cheaper than traditional cloud services. Analysis of the platform suggests inference on Chutes runs at roughly 85% lower cost than AWS for comparable tasks. That’s not a rounding error — that’s a fundamentally different business model.
Pay-as-You-Go, Not Pay-to-Play
One of the things developers genuinely appreciate about Chutes is its pay-per-use pricing model. You pay per query or per token consumed, using either the Bittensor TAO token or regular fiat currency (fiat payments were introduced in April 2025). There’s no minimum commitment, no reserved instances, no “pay us $500/month or else” pricing tiers.
For indie developers and small teams, that flexibility is huge. You can run experiments, test new models, and iterate quickly without burning through budget on idle infrastructure.
It’s Actually Open-Source
This one matters more than people realize. The entire Chutes API codebase is available on GitHub, including all the dockerfiles, API services, and validator code. That openness means you can inspect how the platform works, run your own validator instance if you want to get really deep into it, or fork the project for your own purposes. In a world where most AI infrastructure is proprietary black boxes, that’s genuinely refreshing.
How the Chutes API Actually Works
The “Chute” as a Unit of Deployment
The fundamental building block of the platform is — unsurprisingly — a “chute.” A chute is essentially a containerized AI application that exposes inference endpoints over HTTP. You can use one to run:
- Large language models (LLMs)
- Image generation pipelines
- Text embedding engines
- Speech-to-text or TTS models
- Video generation workflows
- Custom moderation tools
The Chute class itself extends FastAPI, which means if you’ve ever built a Python web API, you’re already most of the way there. You decorate your inference functions with @chute.cord(), give them a public API path, and the platform takes care of routing, scaling, and compute allocation.
Authentication and API Keys
Getting started requires a Bittensor wallet, since authentication is handled via Bittensor hotkey signatures. Once you’re registered, you generate API keys that work with a standard Authorization header on your HTTP requests — straightforward REST API stuff.
If you already own a Bittensor validator or subnet, you can link your on-chain identity to Chutes and get free developer access. It’s a nice perk that encourages builders who are already in the Bittensor ecosystem to experiment on the platform.
Infrastructure Under the Hood
Behind the scenes, the platform routes your API calls to a network of decentralized GPU miners who compete to fulfill requests. Every time an inference runs, the system calculates the cost based on GPU time or tokens processed and distributes micropayments to the miners. The auto-staking mechanism then buys back the subnet’s token and rewards contributors, keeping the whole economy running.
From a pure infrastructure perspective, the platform runs on Kubernetes across a distributed set of nodes. It uses PostgreSQL for data storage, S3-compatible object stores for container images and build contexts, and supports GCS, AWS S3, Cloudflare R2, and Minio for storage backends.
The REST API: What’s Available
The Chutes API reference covers a comprehensive set of endpoints across more than a dozen categories:
- Users — 39 endpoints for account management
- Chutes — 24 endpoints for deploying and managing your AI apps
- Images — 5 endpoints for container image handling
- Instances — 18 endpoints for compute instance management
- Invocations — 6 endpoints for querying inference history and stats
- Jobs — 7 endpoints for batch and async workloads
- Authentication — 5 endpoints for API key management
- Pricing — 6 endpoints for cost estimation and billing
- E2E Encryption — 2 endpoints for encrypted inference (part of the new TEE rollout)
One of the more interesting recent additions is the Trusted Execution Environment (TEE) support, which Chutes announced as publicly available in 2025. TEEs let you run AI inference inside secure, isolated environments where even the platform itself can’t see your data — a major step forward for enterprise use cases and compliance with regulations like GDPR and the EU AI Act.
Real-World Integrations: Who’s Already Using Chutes?
The Chutes API isn’t just a theoretical exercise — it’s already wired into some popular developer tools:
- Roo Code — The popular AI coding assistant lets you configure Chutes as your API provider directly from the settings panel, automatically fetching the full list of available models from your Chutes account.
- Kilo Code — Similar integration, with free API access making it especially appealing for experimentation.
- LiteLLM — Chutes is a supported provider in the LiteLLM library, meaning you can swap it in for OpenAI or Anthropic models with minimal code changes.
- OpenRouter — Chutes-hosted models appear in OpenRouter’s model catalog.
- Janitor AI and KoboldAI — For those building creative AI applications or roleplay tools, Chutes integrates with these frontends by configuring the model name, proxy URL and API key.
The fact that Chutes plays well with LiteLLM is particularly useful for teams already using a provider-agnostic inference layer — you can route specific models or workloads to Chutes for cost savings without rewriting your application logic.
Streaming, Batch Jobs, and Beyond
Streaming Responses
Chutes supports streaming inference out of the box. You define an async generator function in your chute and decorate it with the appropriate cord decorator. Token-by-token streaming works just like you’d expect from any modern LLM API — useful for chatbots and interactive applications where users shouldn’t have to stare at a loading spinner.
Batch and Long-Running Jobs
One area where Chutes goes beyond simple inference is its support for batch processing and long-running jobs. You can define job handlers with @chute.job(), submit batches via a cord endpoint, and get back a job ID to poll for results. For workflows like document processing, bulk embeddings or dataset generation, this async pattern is genuinely helpful.
CI/CD Integration
The platform also supports GitHub Actions-based deployment workflows. You can configure your pipeline to push new chute versions automatically on merge to main, with rollback to previous versions available via the CLI if something goes wrong. For teams trying to maintain production-grade AI services this kind of deployment pipeline support matters a lot.
Chutes API vs OpenAI Pricing: A Direct Comparison
This is probably the question most developers actually care about. OpenAI’s GPT-4o charges roughly $2.50 per million input tokens and $10.00 per million output tokens as of mid-2025. Comparable open-source models running on Chutes — like Llama 3.1 70B or Mistral Large — come in at a fraction of that cost, often under $0.40–$0.80 per million tokens depending on the model and load.
Here’s what the math looks like for a real-world use case. Say you’re processing 50 million tokens a month for a mid-sized SaaS product:
| Provider | Model | Est. Cost / 1M tokens | Monthly Cost (50M tokens) |
|---|---|---|---|
| OpenAI | GPT-4o | ~$5.00 avg | ~$250 |
| Anthropic | Claude Sonnet | ~$4.50 avg | ~$225 |
| Chutes API | Llama 3.1 70B | ~$0.60 avg | ~$30 |
| Chutes API | DeepSeek V3 | ~$0.40 avg | ~$20 |
That’s not a small difference. At scale — millions of users, billions of tokens — the Chutes pricing model represents a fundamentally different cost structure for AI-native products. The tradeoff is that you’re working with open-source models rather than frontier proprietary ones, but for a large and growing number of use cases, that’s an entirely acceptable tradeoff.
Note: Token pricing on Chutes fluctuates based on miner availability and model demand. Always check the live pricing API or your account dashboard for current rates before committing to production budgets.
What About Latency? Is Decentralized Compute Slower?
Let’s address the elephant in the room, because it’s a fair concern. When you route requests through a decentralized network of GPU miners rather than a hyperscaler’s own data centers, does latency suffer?
The honest answer is: it depends, but less than you’d expect.
Time-to-First-Token (TTFT)
For streaming LLM inference — where time-to-first-token matters most to user experience — Chutes typically performs within 10–20% of centralized providers for popular always-on models. The platform maintains “permanently hot” instances of its most popular models, meaning there’s no cold-start delay for those. For less common models or custom deployments, you may see occasional cold-start times of a few seconds while a miner picks up the job.
Throughput and Tail Latency
For batch processing and high-throughput workloads, Chutes can actually outperform some centralized providers by routing to multiple miners in parallel. The P99 tail latency — the worst-case response time — is a bit more variable than AWS or Azure, partly because the miner network is distributed across geographies without the same regional routing guarantees of a hyperscaler.
Practical Guidance
- Real-time chat applications: Use always-on popular models (DeepSeek, Llama 70B, Mistral) — latency is comparable to centralized providers.
- Background processing / batch jobs: Chutes is excellent here; latency variability doesn’t matter, and cost savings are maximized.
- Ultra-low-latency applications (<100ms SLA): Proceed with caution and benchmark thoroughly before committing.
- Custom or niche models: Expect occasional cold starts; build retry logic and a reasonable timeout into your client.
The Chutes invocations API gives you per-request timing data, so you can profile your specific workload rather than relying on general benchmarks.
Pros and Cons of the Chutes API
Pros
- Dramatically lower compute costs — up to 85% cheaper than equivalent AWS inference for many workloads
- No infrastructure management — serverless means you really don’t have to think about GPUs, Kubernetes or Docker beyond your own container definition
- Open-source and transparent — the full platform code is public on GitHub
- Model variety — top SOTA open-source models (DeepSeek, Llama, Mistral, Kimi K2 and more) available immediately after release
- Flexible integrations — works with LiteLLM, Roo Code, Kilo Code, OpenRouter and others
- Privacy-focused — TEE support for secure, encrypted inference
- Pay-per-use — no fixed costs, no wasted budget on idle servers
- Active ecosystem — the #1 Bittensor subnet with a strong developer community
Cons
- Bittensor dependency — the platform’s economics are tied to TAO token mechanics, which adds complexity for teams unfamiliar with crypto infrastructure
- Learning curve for auth — initial setup requires a Bittensor wallet, which is non-trivial for developers with no Web3 background
- Infrastructure complexity if self-hosting — running your own validator instance requires Postgres, Kubernetes, Ansible and serious DevOps chops (though most users won’t need to do this)
- Python-only SDK — as of now, official SDK support is Python only; other languages aren’t supported yet
- Emerging ecosystem — while growing fast, it’s still newer than AWS or GCP and some enterprise tooling is less mature
How to Get Started with the Chutes API
Here’s a quick-start path for developers who want to try it:
Step 1: Create a Bittensor Wallet
Install the bittensor library and generate a coldkey and hotkey:
bash
pip install 'bittensor<8'
btcli wallet new_coldkey --n_words 24 --wallet.name chutes-user
btcli wallet new_hotkey --wallet.name chutes-user --wallet.hotkey chutes-user-hotkeyStep 2: Register and Get an API Key
Head to chutes.ai/app and connect your wallet. Once registered generate an API key from your account dashboard.
Step 3: Install the SDK
bash
pip install chutesStep 4: Write Your First Chute
python
from chutes.chute import Chute
chute = Chute(username="youruser", name="my-llm-app")
@chute.cord(public_api_path="/generate")
async def generate(self, prompt: str):
result = await self.model.generate(prompt)
return {"output": result}Step 5: Deploy
bash
chutes deploy --name my-llm-appThat’s genuinely it. No Dockerfile wrestling, no cloud console clicking. The platform builds the container, allocates compute, and your endpoint is live.
Chutes API vs. Traditional Cloud AI APIs: A Quick Comparison
| Feature | Chutes API | AWS SageMaker | OpenAI API |
|---|---|---|---|
| Pricing model | Pay-per-token/usage | Reserved or on-demand instances | Pay-per-token |
| Relative cost | ~85% cheaper than AWS equiv. | Baseline | Moderate–High |
| Model selection | Open-source SOTA models | Limited managed models | Proprietary models |
| Self-deployable models | Yes | Yes (complex) | No |
| Open-source platform | Yes | No | No |
| Streaming | Yes | Limited | Yes |
| TEE / encrypted inference | Yes (new) | No | No |
| Crypto payment option | Yes (TAO) | No | No |
Cost Savings Calculator
Chutes API cost savings calculator — compare your monthly AI inference costs against OpenAI and AWS
Monthly tokens (millions)
100M
Chutes monthly cost
$60
vs. selected provider
$500
Monthly savings
$440
Estimates based on publicly listed pricing as of mid-2025. Chutes rates vary by model and miner availability — verify at chutes.ai/pricing.
Growth Metrics Worth Knowing
The numbers here tell a real story. According to IQ.wiki’s analysis, Chutes saw a 250x increase in demand between January and May 2025, reaching the 100 billion tokens per day milestone by late May. The platform’s TAO-based subnet holds a market value of approximately $100 million, making it the largest subnet in the Bittensor ecosystem by value.
Founder Jon Durbin has spoken publicly about the vision of making Chutes the “Linux of AI” — open, decentralized, and the default substrate that developers build AI applications on, rather than proprietary cloud services. Given the growth trajectory, its not an unreasonable ambition.
Frequently Asked Questions
Do I need to know anything about crypto to use Chutes API?
For basic usage — querying existing models via API — you mainly need to understand API keys. The wallet setup is a one-time hurdle and doesn’t require deep crypto knowledge. Fiat payment support added in 2025 makes it easier for teams that don’t want to hold TAO.
Can I deploy my own custom model on Chutes?
Yes. The platform lets you bring your own Docker container or define custom images using the SDK’s Image class. You can install any Python dependencies and load models from Hugging Face (including private repos with a token) or your own storage.
Is Chutes API suitable for production workloads?
Increasingly, yes. The platform explicitly targets production use cases with always-on models, batch processing, and the newly added TEE support. Integrations with CI/CD tools and monitoring via Prometheus metrics suggest its maturing fast. That said, teams with strict SLA requirements should evaluate carefully and test throughput and latency for their specific models.
What models are available right now?
The catalog changes frequently — the team deploys new SOTA models within minutes of release. As of mid-2025, the catalog includes DeepSeek, Meta Llama, Mistral, Kimi K2, and many others across LLM, image, speech and video categories. Browse the live catalog at chutes.ai/app.
How does billing work?
You pay per usage — per token for LLMs, per second of GPU time for other workloads. You top up a balance and costs are deducted per invocation. The pricing API has six endpoints for querying current rates, so you can estimate costs programmatically before running workloads.
The Bigger Picture: Why Decentralized AI Compute Matters
There’s a broader trend worth paying attention to here. The AI world has largely consolidated around a handful of providers — OpenAI, Anthropic, Google DeepMind — for frontier models, and AWS, Azure and GCP for compute. That concentration creates real risks: price hikes with no competitive alternatives, censorship of outputs, vendor lock-in, and data privacy concerns.
Chutes represents a different bet: that decentralized infrastructure, combined with the open-source model ecosystem, can deliver comparable or better capabilities at a fraction of the cost while preserving developer autonomy. The platform’s support for GDPR/CCPA compliance and it’s new TEE features show that “decentralized” doesn’t have to mean “unregulated” or “insecure.”
For developers building AI-powered applications today its worth seriously considering where your inference is coming from — and whether the economics of centralized cloud AI actually make sense for your use case.
Conclusion: Should You Be Using the Chutes API?
If you’re building with open-source AI models and you haven’t looked at Chutes yet you’re probably leaving money on the table. The cost advantages are real, the developer experience is genuinely solid, and the ecosystem integrations mean you likely don’t have to rewrite much of your existing code to plug it in.
For teams and individual developers on a budget it’s a particularly compelling option — you get production-grade LLM inference without the cloud bill that usually comes with it. For enterprise teams the new TEE support and GDPR-alignment make it worth a serious evaluation, even if you’ll want to test thoroughly before switching from more established providers.
Key takeaways:
- Get started at chutes.ai/app — the platform is live and the free tier lets you explore before committing.
- Check the official API reference to understand what’s available and plan your integration.
- If you’re already using LiteLLM, Roo Code or Kilo Code you can connect Chutes in minutes without rewriting anything.
- Follow @chutes_ai on X for model releases and platform updates — new SOTA models often appear there first.
- For deeper infrastructure details, the GitHub repository is fully public and worth a read.
The Chutes API isn’t just another AI inference endpoint. It’s a bet on what AI infrastructure looks like when it’s built out in the open, without the margins of a cloud monopoly baked in. And judging by the growth numbers so far, a lot of developers are taking that bet seriously.
Visit: Swifttech3

